
Woorank, das Addon für Firefox
Wir benutzen hier zur Analyse das Firefox Addon für Woorank (funktioniert so nur im Browser Firefox!) https://addons.mozilla.org/de/firefox/addon/seo-website-analysis/?src=search
Nach der Installation könnt ihr eine Website analysieren
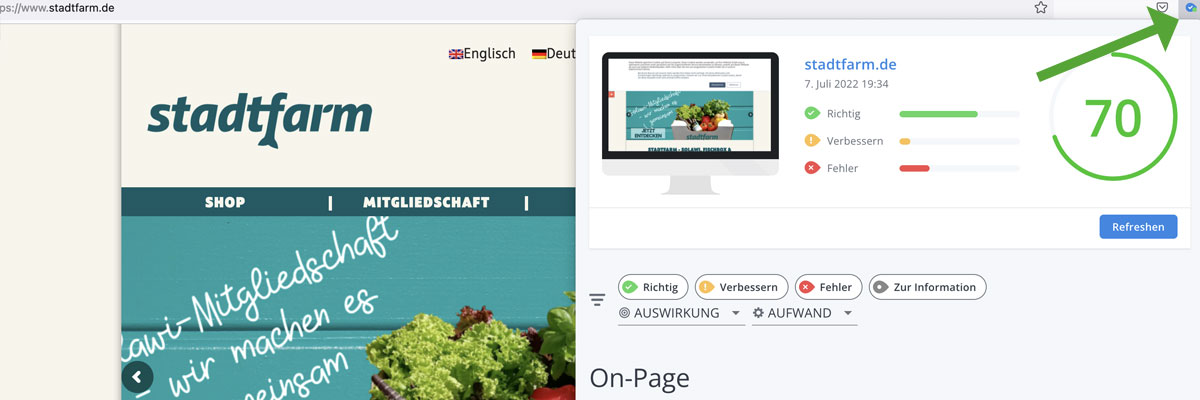
Struktur durch Überschriften
Überschriften H1-H6 → HTML-Überschriften, für Google wichtig sind H1-H4 –> egal, welche Website-Technik, raus kommt immer HTML. Im HTML haben die Überschriften bestimmte Textgrößen. H1 ist am größten und je geringer die Überschriftenordnung, desto kleiner die Textgröße.
i.d.R → H1 pro Seite 1x, die anderen logisch verschachtelt mehrmals
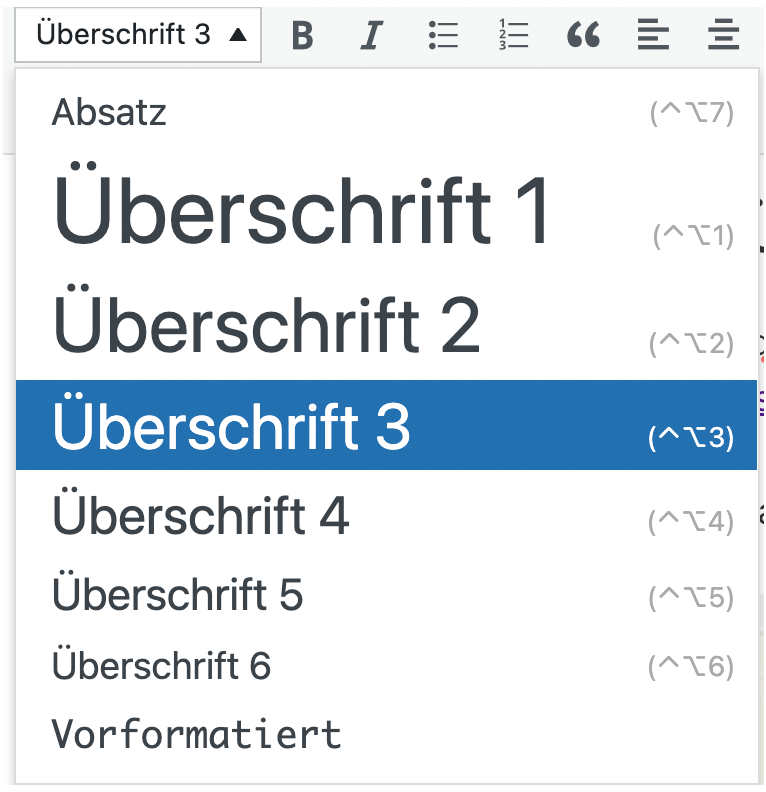
<H1>…</H1>
Absatz mit Text, bezug nimmt auf die H1
<H2>…</H2>
Absatz mit Text, bezug nimmt auf die H2
<H3>…</H3>
<H4>…</H4>
<H2>…</H2>
<H3>…</H3>
<H4>…</H4>
<H3>…</H3>
<H4>…</H4>
<H4>…</H4>
<H2>…</H2>
Typographie & Struktur – kein Widerspruch durch CSS
Wenn du ein bestimmtes Layout verwirlichen möchtest, und dazu die die Überschriften geschickt einbinden möchtest, ist die Lösung CSS, der Layoutsprache für HTML.
Optische Größe kann von der Gewichtung der Überschrift abweichen (CSS)
h1 Technische Probleme bei VW
h2 Wieder einmal der Dieselskandal
Strukturieren des Textes
… durch
- Aufzählungen,
- Fett,
- Kursiv,
- Zitate (blockquote)
- Bilder
- Videos
- Podcasts
- Verlinkungen
- intern
- extern
Struktur durch Tags
(Buch ab S. 649, Kapitel 10.1. → Onpage Optimierung)
Optimierung durch Tags
Meta Tags: Title & Description
Title: Solidarische Landwirtschaft – Markttage – Fisch & Gemüse
Description: Von der Gemüsebox zur solidarischen Landwirtschaft. Wir…

Check: Woorank → Bildung des SERP Snippets
https://addons.mozilla.org/de/firefox/addon/seo-website-analysis/?src=search
Check: Über Quelltext
herausfinden https://digitalfahrschule.de/element-untersuchen-im-chrome/
Element untersuchen
Meta Tag: Canonical Tag
der benutzt wird, um auf eine Hauptseite zu weisen.
>>>> Dieser Tag vermeidet doppelten Content
Grund: Bei Shops & CMS werden durch die Technik doppelte Seiten gebildet
- shop.de/Schuhe/turnschuh-nike-groesse-41.php
- shop.de/Schuhe/page?12345
- shop.de/Warenkorb/Schuhe/turnschuh-nike-groesse-41.php
Über den Canonical Tag weist man im head (Quelltext-Kopfbereich) Seite 2 & 3 darauf hin, dass die Hauptseite die Nr. 1 ist
<link rel=„canonical“ ref=„https://shop.de/Schuhe/turnschuh-nike-groesse-41.php „>
Meta Tag Robots
Indexierung – follow, no-follow
<meta name=”robots” content=”index, follow”>
<meta name=”robots” content=no-follow”>
z.B. Wikipedia verlinkt intern (innerhalb von Wikipedia.de) mit Follow-Links (der Crawler klettert an der Linkstruktur lang & sammelt die Inhalte) und nach extern mit No-Follow Links, d.h. fordert die Crawler auf, die Adresse nicht weiterzuverfolgen.
- index erlaubt das Indexieren von Websites, Standard, wenn nichts angegeben wird.
- follow bewirkt, dass der Crawler alle Links auf der Seite verfolgt und zur Indexierung untersucht, Standard, wenn nichts angegeben wird.
- noindex sorgt dafür, dass eine URL nicht indexiert wird oder aus dem Index entfernt wird, sollte sie bereits aufgenommen sein.
- nofollow verhindert, dass ein Crawler die Links der URL weiterverfolgt. Das bedeutet aber nicht, dass die Ziel-URLs von anderen URLs aus nicht verfolgt und ggf. indexiert werden können.
Indexierung
<meta name=“robots“ content=“noindex“> → z.B. mein Impressum aus den SERP heraushalten will → Sitelinks
Archive – Cache
<meta name=“robots“ content=“noarchiv“ />
→ die Webseite nicht in den lokalen Zwischenspeicher (Cache) der Suchmaschinen aufgenommen.
Google stellte als erster Anbieter Kopien von Webseiten zur Verfügung, die in der Trefferliste unter dem Link Im Cache betrachtet werden können, auch wenn die ursprüngliche Seite auf dem Webserver sich bereits verändert hat oder nicht mehr existiert.